Setting the foundation for analytical computation discussions
We submit our job, wait, and we get an answer. Everything is great when we are discovering and developing. When you are trying to scale frequency, size, response time, and (or) quantity, you probably want faster run times. Faster also opens doors to more methods and approaches. In my experience, faster breeds creativity! To kick this blog off, I want to break faster down into types (and a few subtypes). Future posts can refer back to this post, as well as dive deeper into them. For the time being, let’s take data size and IO speed out of the conversation.
A quick lingo check
- Session - the invocation of the software system you are using. In batch processing, this is tied to job submission rather than interacting with an application iteratively.
- Jobs - the full set of code you are submitting for execution
- Steps - the individual commands in the code that request computation and wait before proceeding
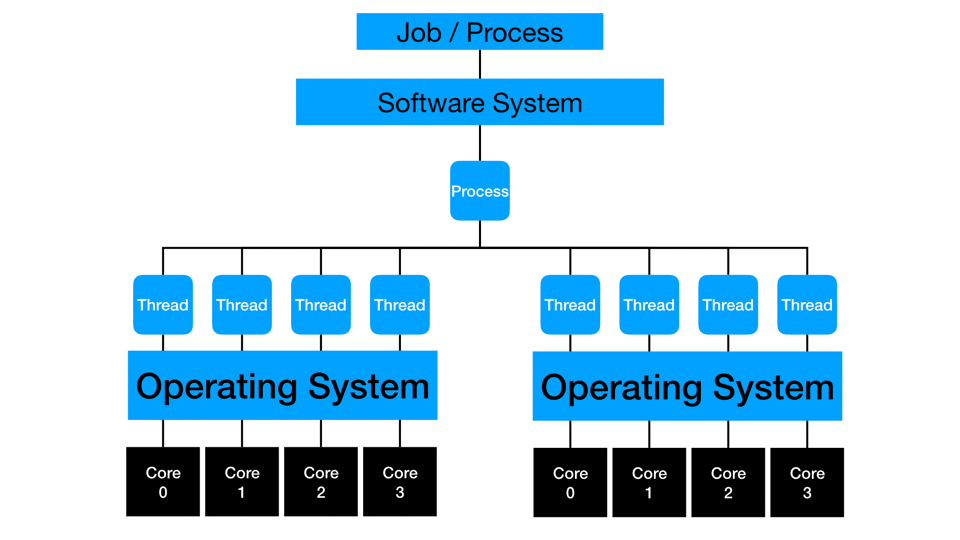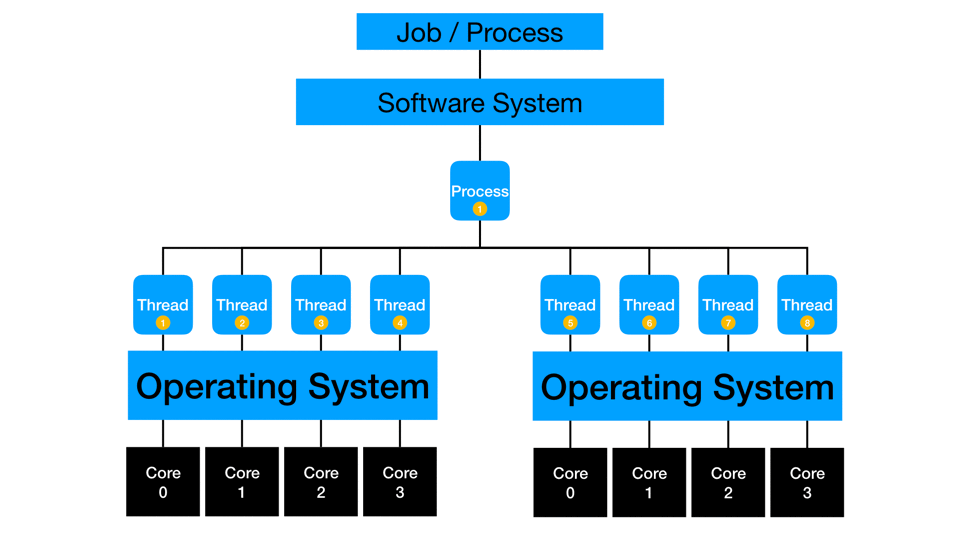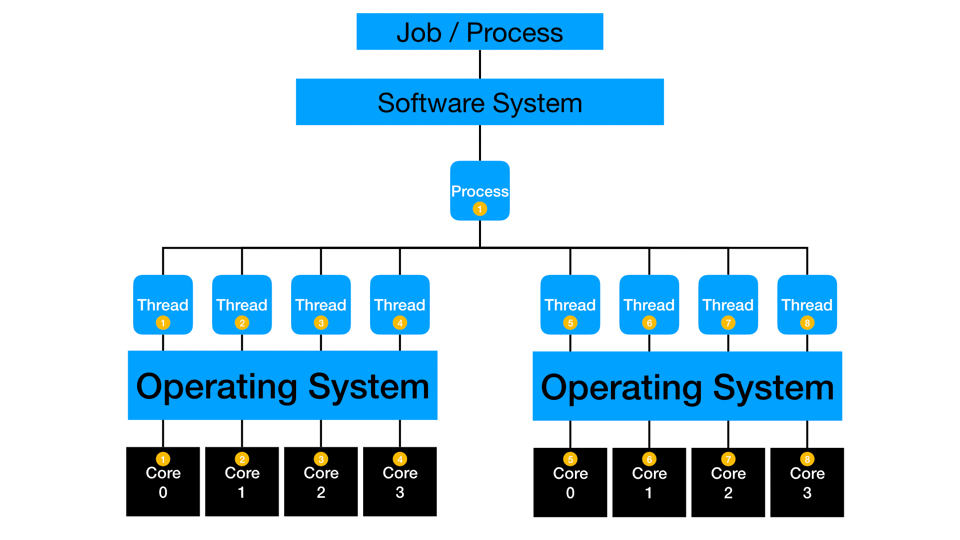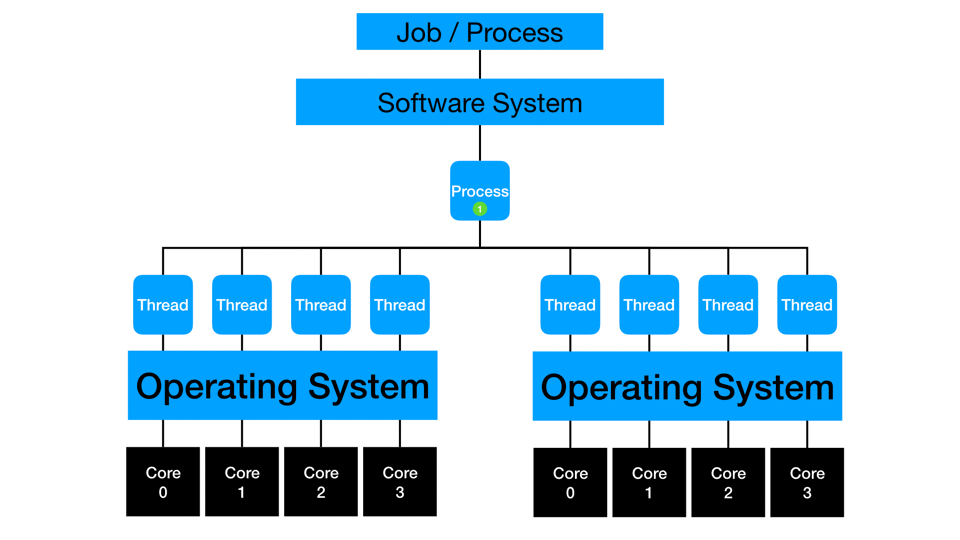
- Process - the action level of the runtime engine you are using. Sometimes congruent to the step level but frequently a software system (Python, R, SAS, various packages within these, etc.) breaks down user-submitted steps into sub-levels of action, which may or may not be directed by user input.
- Thread - the execution sequence of instructions submitted to a processor
Types of Computing
- Single-Threaded: process running on a single thread
- Sequential Single-Threaded: processes running on a single thread, sequentially
- Concurrency processes running independently either sequentially, at the same time, or with a processor switching between them
- Parallelization: Splitting a process into processes that run in parallel
- Multi-Threading: Spreading a process over multiple threads = multi-threaded
- Distributed Computing: Spreading a process over multiple threads and machines
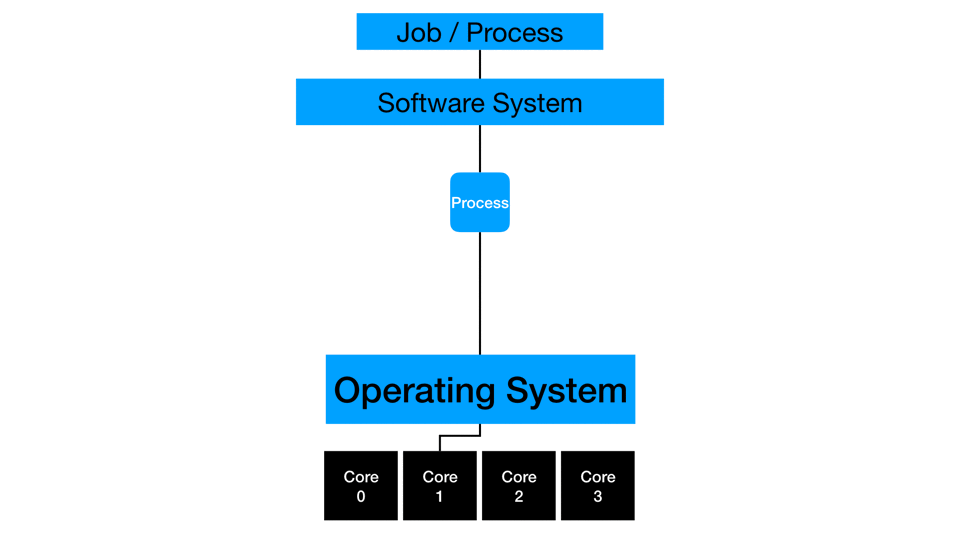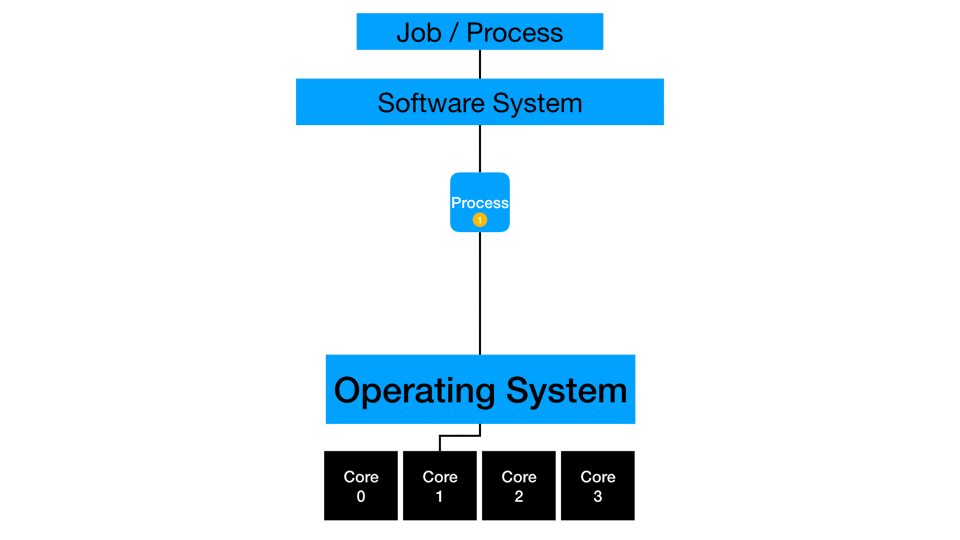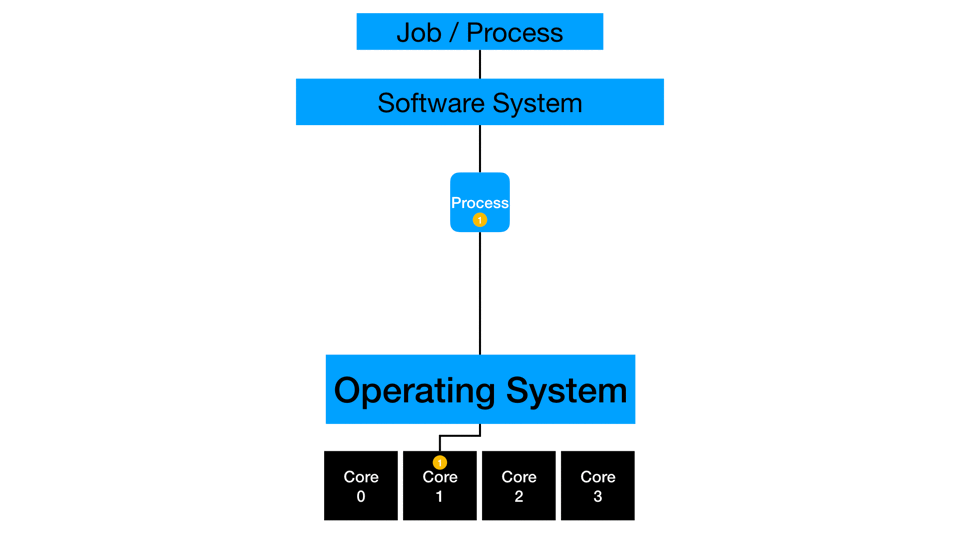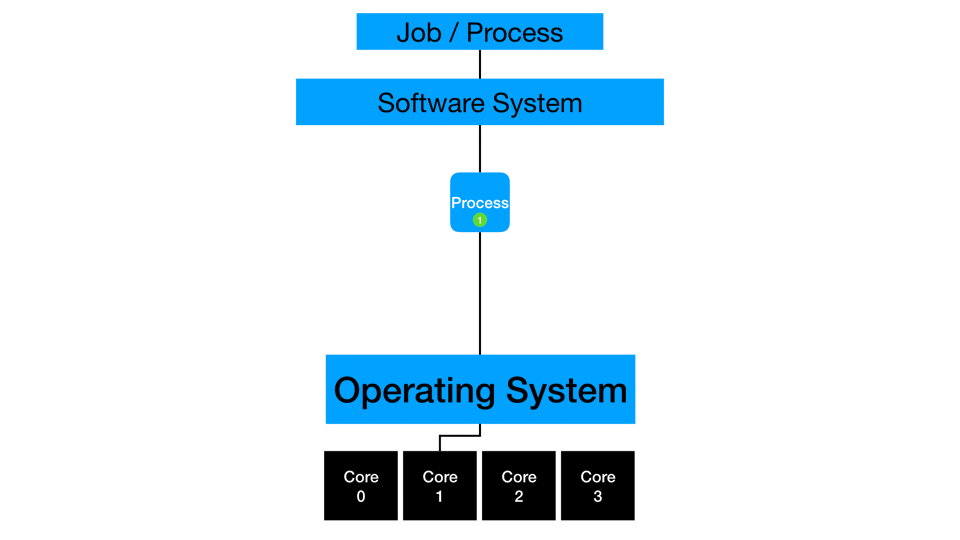
Single-Threaded
Some processes run on a single thread by design or constraint. At this core level of execution, generating faster run times may be achieved with faster processors, less competition for computing resources, faster IO, and concurrency.
Sequential Single-Threaded
When a process runs on multiple subsets of data (states, patients, companies, etc.) it may execute on this one-at-a-time. Loading all data to memory to kickoff this single process can optimize runtime. This type of execution is essential because the size of data may require manually running the subsets separately on the system you are executing on.
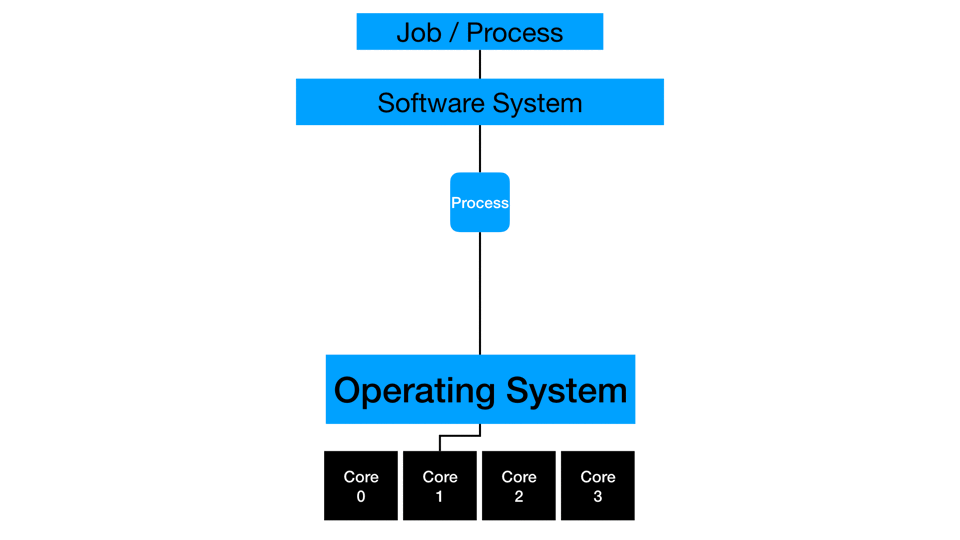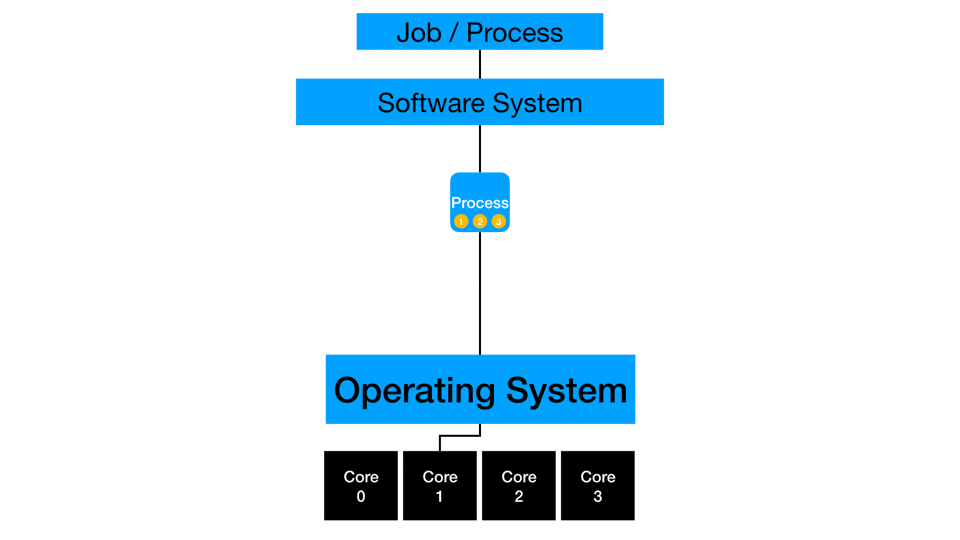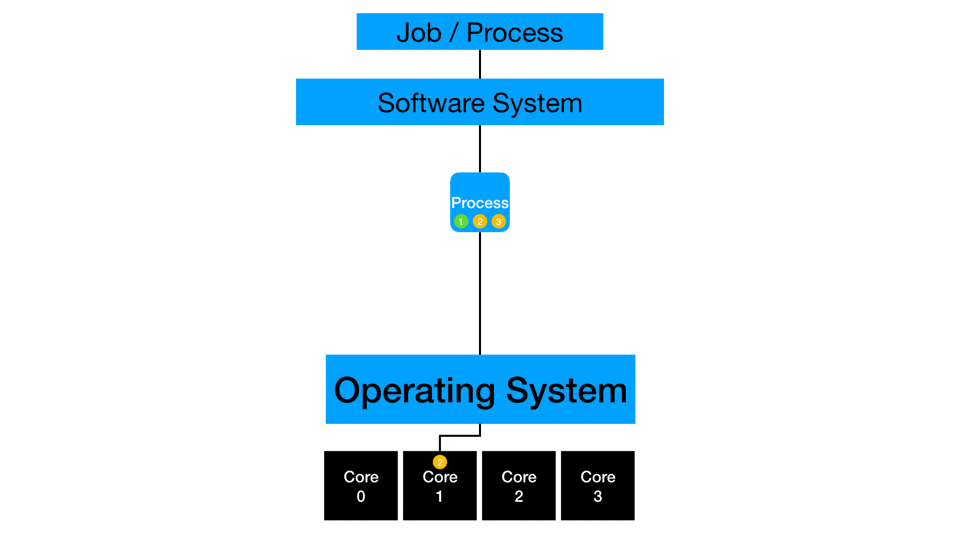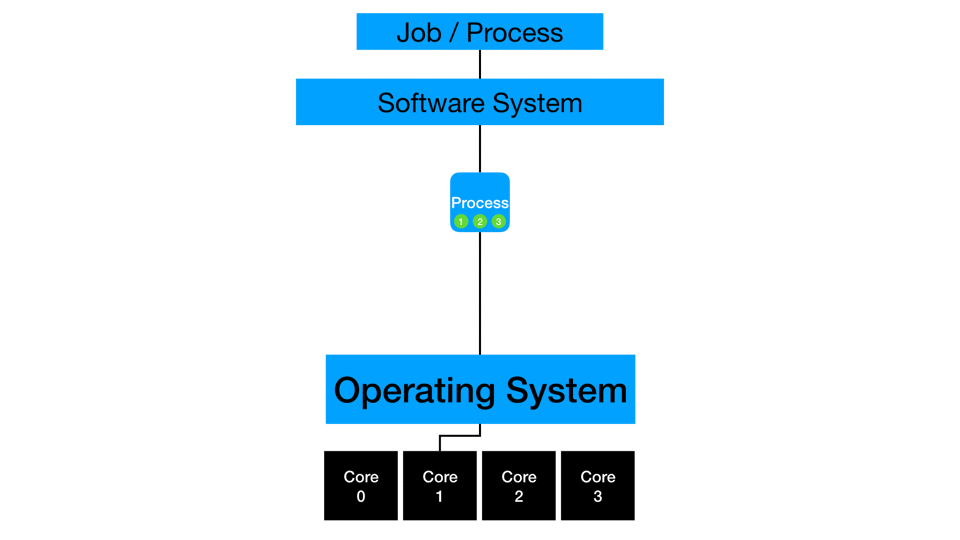
Concurrency
On the computing side, processors can divide independent work and even switch between them to optimize subtask like data loading. A processor executes part of a process where data is available while another independent task is waiting on data to load. Modern processors are very efficient at context switching like this and even employ things like hyper-threading to manage multiple channels of information into a processor. While not true parallelization (covered in the next section), this is the efficient management of independent instructions by a processor.
Parallelization
Parallelization involves programmatically instructing sequential computations to compute at the same time. It is essential to consider the computation time for the individual processes as this method can only be as fast as its slowest single-threaded process. Design your code to create parallel processes and manage them before continuing to further steps. This method works in a scaled-up environment (hardware with more cores) and a scaled-out environment (more hardware). This method can also overlap related sequential processes through pipelining - where one process’s output feeds another process’s input dynamically. It is also beneficial to consider using a load balancer to manage the individual processes in a scaled-out environment.
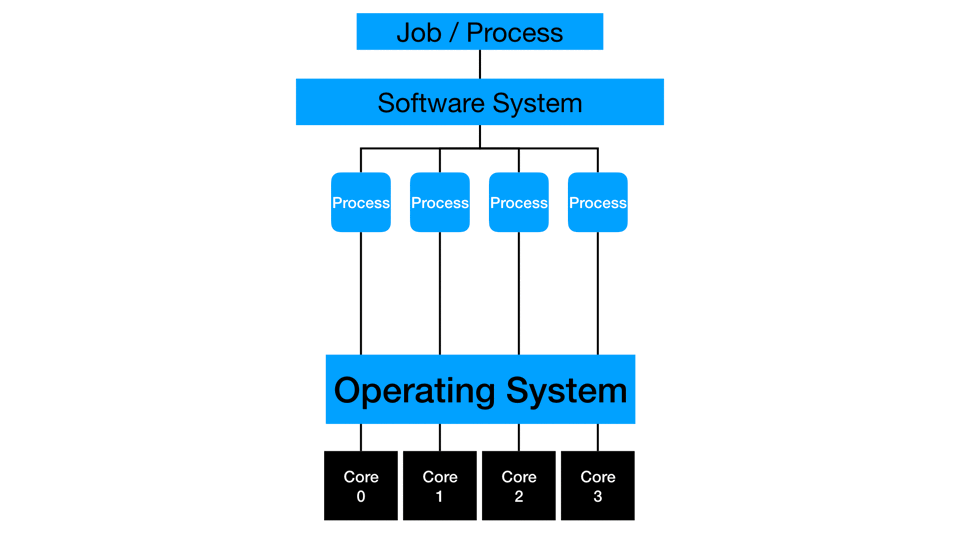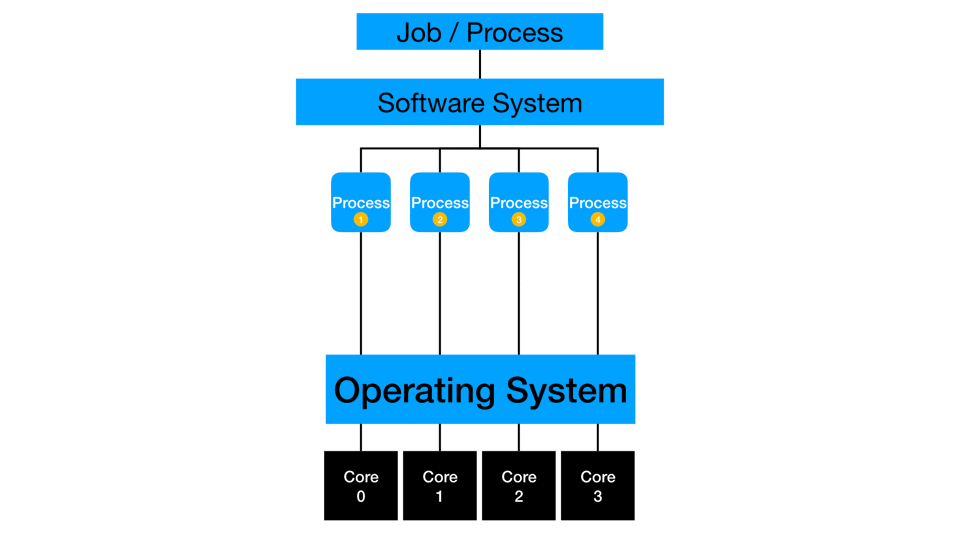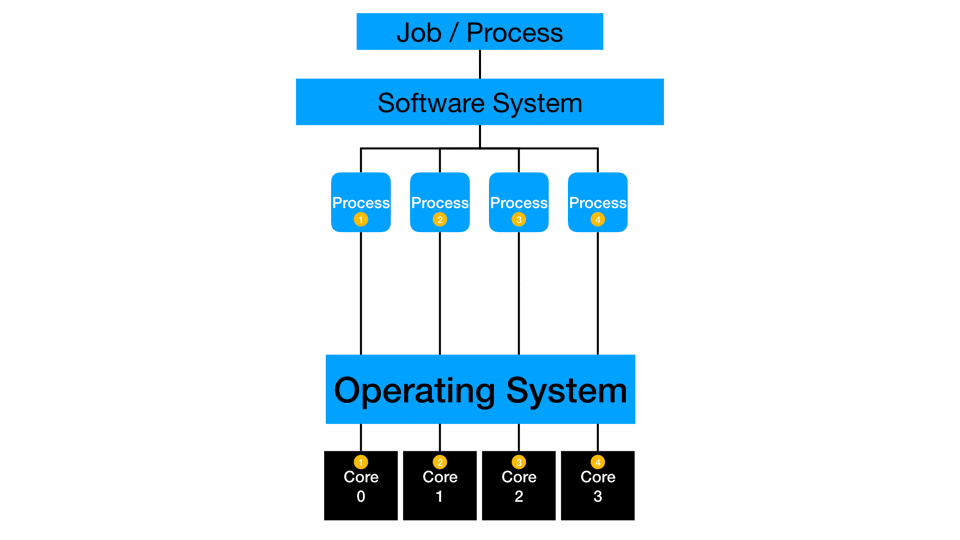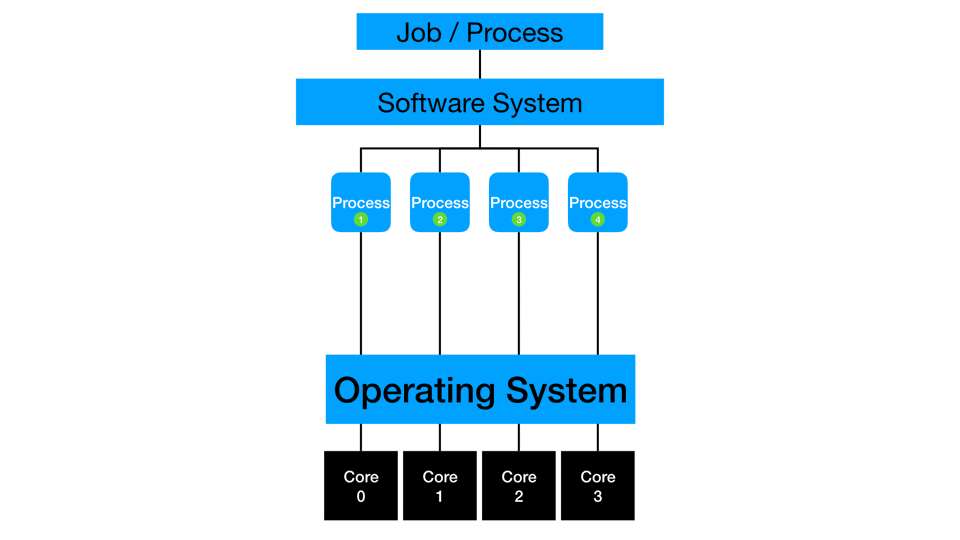
Multi-threading
Some processes fully or partially work multi-threaded, where multiple cores on a single machine can simultaneously work on the same process. Many algorithms are improved to take advantage of multi-threading and concurrency. Sometimes, the process is only optimized to handle parallelization opportunities via multi-threading. I suggest checking your software systems for updates to existing procedure steps or new replacement procedure steps that are capable of multi-threading. A vital system consideration is that there may be a constraint on any running job to work on a sub-capacity of the total system, which limits multi-threaded computations. I frequently test my jobs across a range of thread-counts to find a locally optimal value for my process. At the programming level, you should test and consider the impact of multi-threading for your current data and process. Some situations can slow down with more threading as the constraint moves to another part of the computing platform.
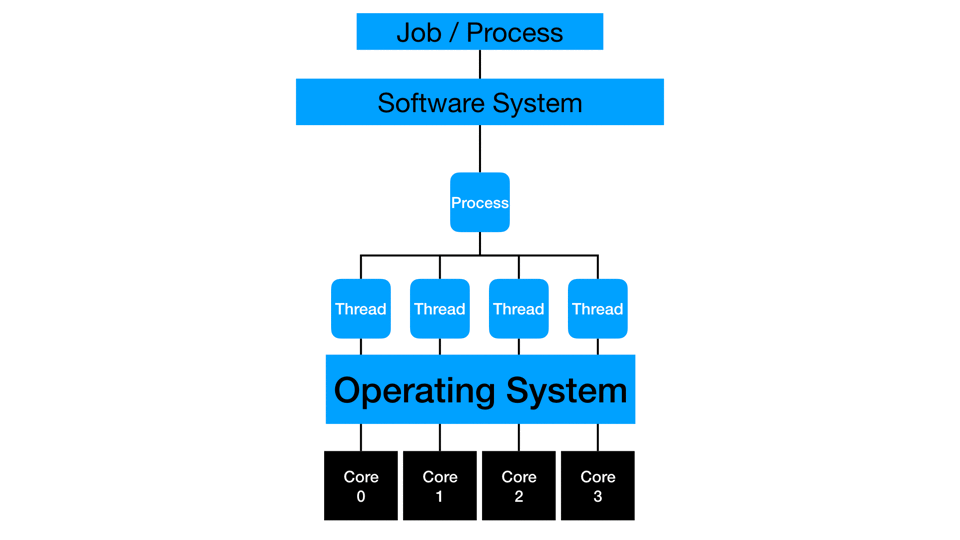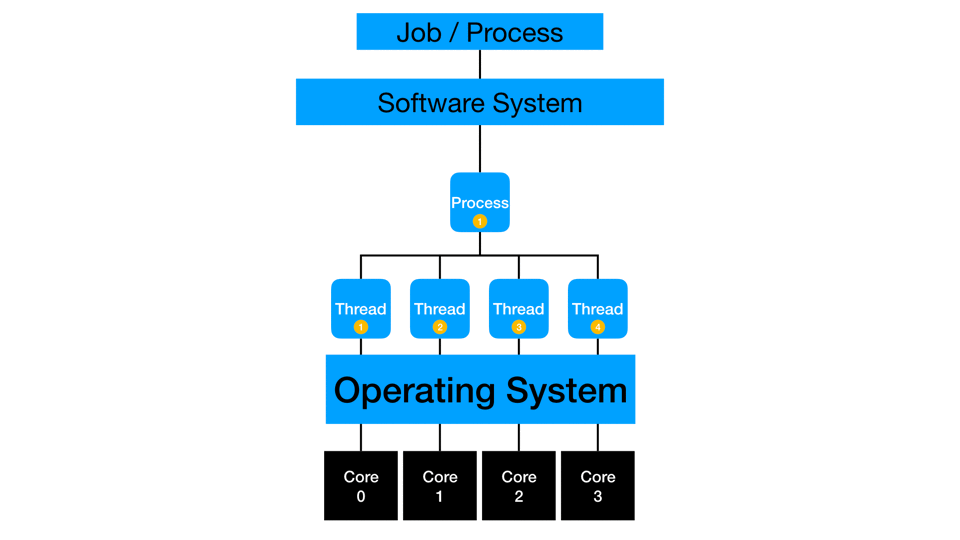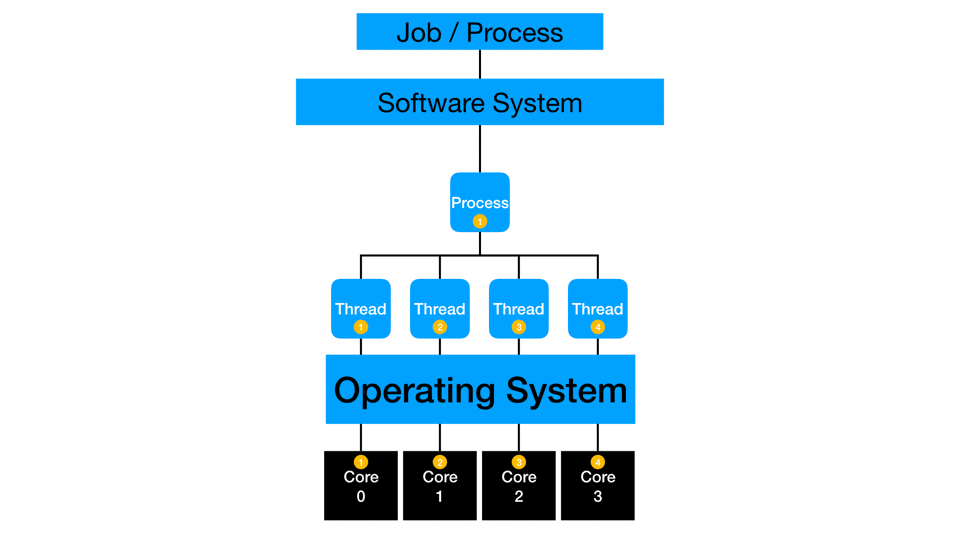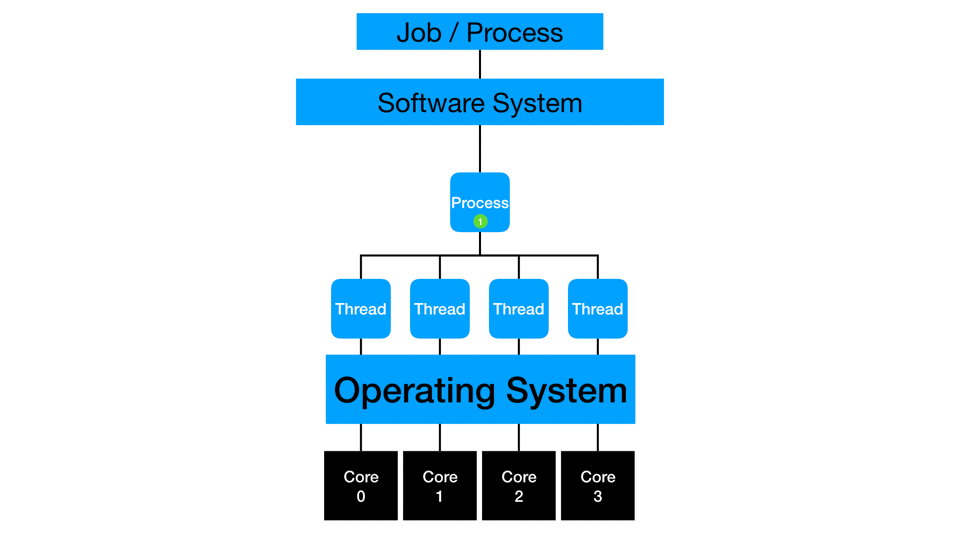
Distributed Computing
Distributed computing distributes multi-threading to more than one piece of hardware. The cores of multiple machines simultaneously work on the same process or action. Distribution typically also involves in-memory processing where data gets partitioned such that and subsets of rows are loaded to each machine in a distributed cluster. Depending on the type of process, the threads may work independently and then collect the final answer at the end of processing, or they may simultaneously compute and communicate with each other to create the final answer. One example is calculating a mean: each thread can sum and count a small subset of data, then the collection phase has to sum the sums, sum the counts, divide, and get the overall mean. Another example is calculating a median: each thread needs to communicate with the other threads to compare values and ranges before estimating the actual median across all the rows of the full data.
One response