Dear Reader,
March 8 - 11, 2020, were intended to be exciting days of collaboration and sharing at PHUSE US Connect 2020. Like so many 2020 events, this one canceled due to Covid-19. I am thankful this organization was one of the early adopters of the concept of “flattening the curve.”
With no event, the content still lives on. In this post, I share the presentation I prepared in this open forum in hopes that I can engage you and get feedback.
Thank You,
Mike
Outline
Introduction
Heads Up! While most of my posts are on the technical side of planning and doing analysis and data flow, this one is about applying a new idea to a dated process. It is not yet in place, but my view is that this is a solution to an outdated method. I welcome your feedback on what you are about to read. The original goal was to present this at PHUSE in the hopes of getting real-time feedback.
| Slide 1 |
|---|
 |
Clinical trial monitoring that necessary yet unexciting process is the key to more efficient trials. Efficient? At first, efficiency is just getting from the first patient to completed analysis as fast as possible. The exciting part of efficiency is that the closer we get to real-time data monitoring, the closer we get to implementing more complex innovative trial designs. Making decisions faster and with more accuracy is the prize at the end of the complexity.
| Slide 2 |
|---|
 |
Technology is not just a showcase of what is possible. It is a necessity for progress. Here we talk about software, but technology is anything developed from scientific knowledge. Imagine that moment they first put a saddle on a horse. It was a comfortable leap forward, but luckily improvement didn’t stop before we got the train, car, plane, and rocket. This presentation focuses on implementing newer technology to enable positive change to a tried-and-true process.
Background
| Slide 3 |
|---|
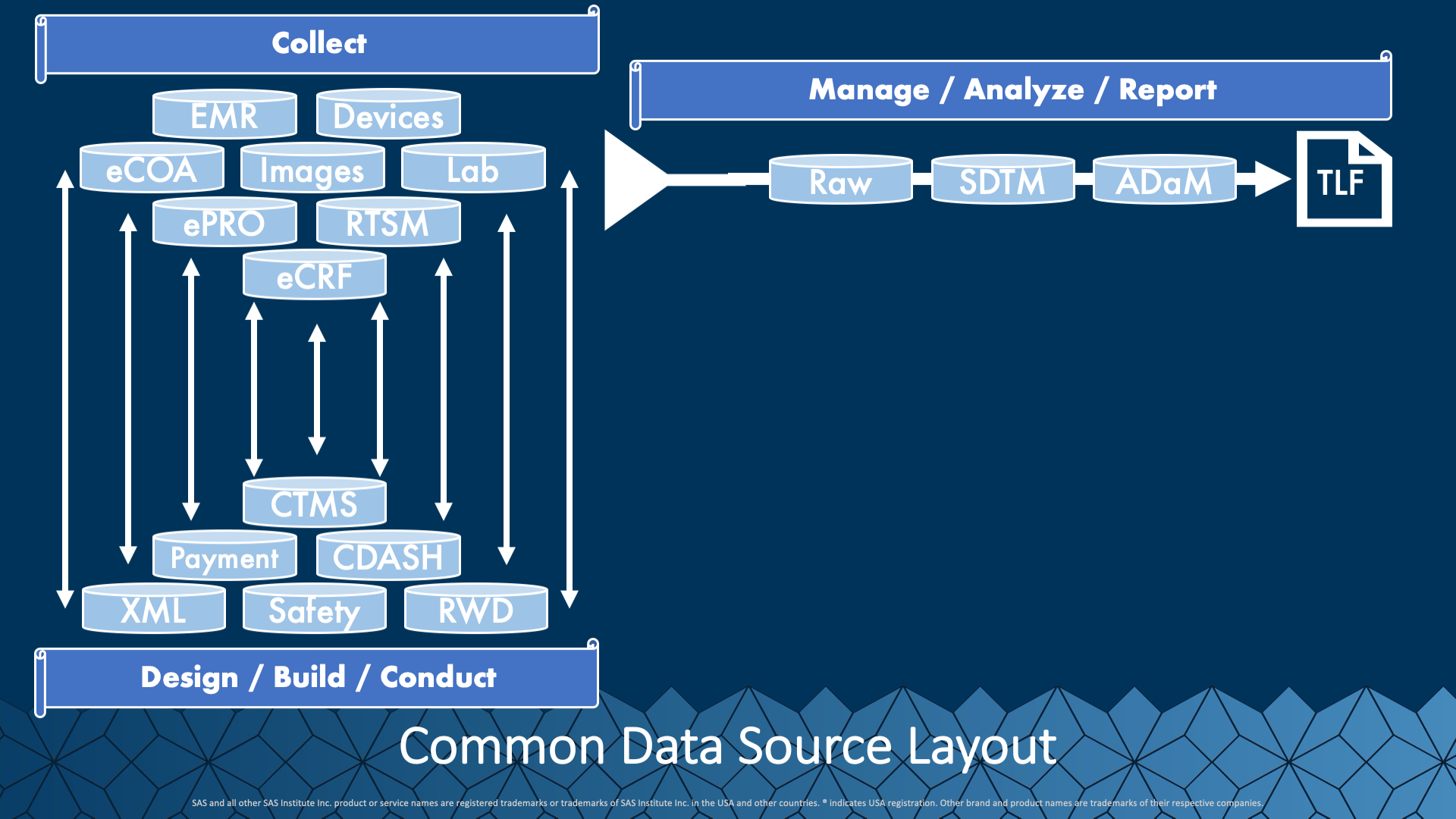 |
Let’s first take a look at the data landscape for clinical trials. In this chart, we see a sampling of the various data collection systems communicating with the methods we manage and house information for consumption, review, and standardizing. On the right, we see a typical extraction, filtering, and shaping process that takes data from its export status, called raw, through standardization to standards (SDTM, ADaM), and into the review state of TLF’s. This high-level view is comfortable but perhaps not wholly representative of what happens.
| Slide 4 (Click-to-Play) |
|---|
In this picture, a zoomed-in view of the process reveals more of the reality of the process. Data get extracted from a system, the eCRF. It involves many substeps like planing the export, preparing the export, file creation, discovery of new/updated files, transferring the data, and storing them where they process through standards to the TLF state. Then the processing picks up and extracts info, transforms the shape, stores in the appropriate locations, and creates and updates reports. Then, the consumers discover and review the reports. All this does not just happen at the end of the trial; instead, it is happening continuously, in hopes of finding data issues as soon as possible and making the right information available throughout the trial conduct time. Whew!
| Slide 5 |
|---|
 |
The Chicago skyline! Pick any two office windows. Maybe in adjacent buildings, or even across town from each other. How would you move an item from one office to another? Package it and ship it by currier? That is very involved: prepare, schedule, pickup, transport out of the building, to another building, to the other office, handed off, picked up, opened. If we use email, we still have to prepare, schedule, pick up, and review before the information gets exchanged. Similar to how we handle our trial data today.
A New Way
| Slide 6 (Click-to-Play) |
|---|
We could just speed the process up, like making faster cars, streamlined traffic, optimized elevators, and have you. But that can only improve the process so much. We need a new way of transporting the data. Think about a direct connection between the source and the result that continuously runs the bottled up process while sensing changes and immediately updating the consumption point.
| Slide 7 |
|---|
 |
Imagine streams connecting to tributaries flowing into rivers that connect to an ocean. In this world, there is a complete connection. It may seem chaotic, but gravity and flow keep everything moving and working. Let’s design a clinical trial data system that streams like this.
Streaming Concepts
| Slide 8 (Click-to-Play) |
|---|
As a brief intro to streaming data concepts, we will construct the idea with standard terms. Data points are events, and a streaming engine can monitor them. The engine can route the data through projects that contain one or more continuously running points of logic, called queries. Queries include pieces called windows that can connect to storage locations to save updated results. The events can read by subscribing and even alter data by publishing back. To conceptualize publishing, think about edit checks that run outside of an eCRF application. On that thought, we can put a typical example on top of this lingo in the next slide.
| Slide 9 (Click-to-Play) |
|---|
Think about subscribing to data in an eCRF system. As data are entered or edited, the changes route through a streaming engine project. For this simple example, we will say the project is staging the data for SDTM standards. A specific task in this would be combining information from eCRF and Labs to create the DM and LB tables in the SDTM specification. If new lab data is detected, it could be merged with eCRF information and immediately update the current version of the LB table stored as a SAS dataset.
Scaling
| Slide 10 (Click-to-Play) |
|---|
Scaling the concept of continuous running queries as projects in streaming engines is very modular. There can be multiple engines stored in various locations that run relevant local projects. The projects can even interconnect to share information. The windows within projects configure to do any project. A key focus of advancement in monitoring is analytical techniques applied to data in near real-time. Field and cross-field edit checks just made a giant leap forward in capability and reusability!
| Slide 11 |
|---|
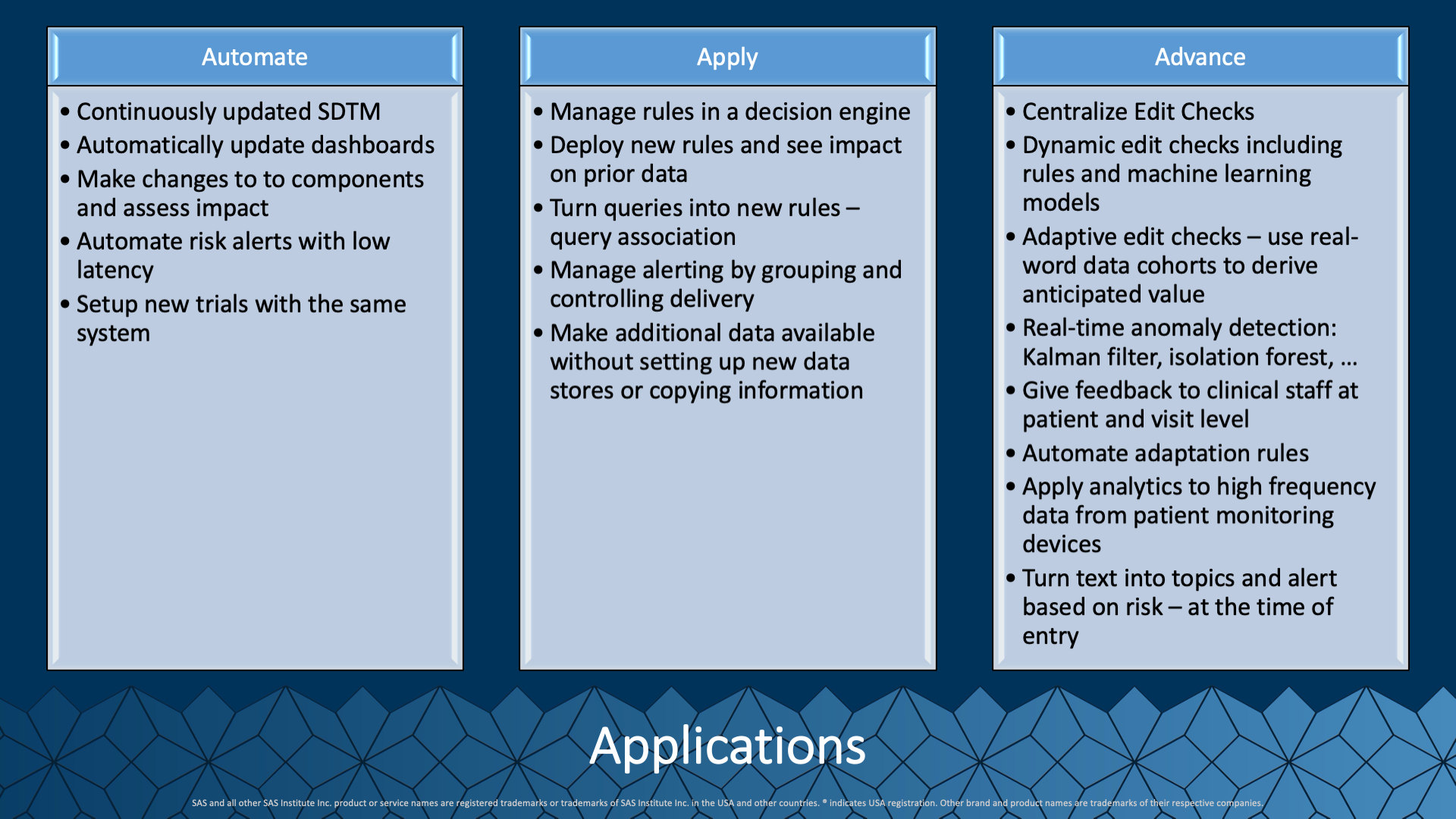 |
With the brief descriptions of this new way of approaching the clinical trial data process, it should be possible to envision a new way forward. We are automating every day, highly repetitive tasks to make them assets instead of speed bumps. With automation comes the ability to apply many more processes against data, like checks for validity and confidence. Stretching beyond our expert derived rules, we can start to augment this with automated analytical methods that detect and predict areas where monitoring efforts focus on higher-quality clinical trial data.
Conclusion
| Slide 12 |
|---|
 |
Thank you for reviewing this idea. What are your thoughts on this? I hope we quickly see the application of similar technologies to clinical trial data processes. It will be a big leap forward to move beyond designing efficiencies to the existing process and designing a new one that automates more and advances quality through the application of technology.